Since lately the installer seems to be a little unreliable I decided to try the manual way and screenshot the whole process so that it might be of help to others.
The first thing to do is install Ruby for Windows, which can be conveniently fetched from http://rubyinstaller.org/. I recommend you pick version 1.9.2 which, at the moment, I believe is the version used by most of the Sproutcore developers.
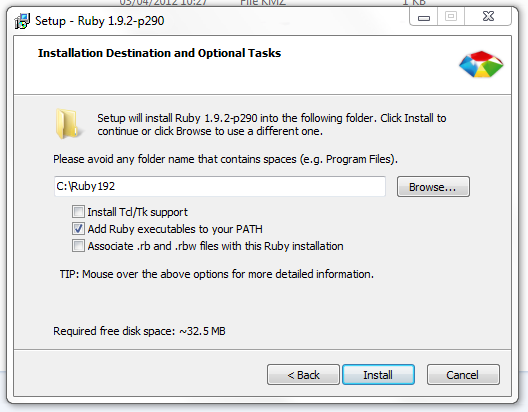
If unsure just tick the box.

gem install sproutcore
and wait for the whole process to end. The full output is shown in the image on the right. Sproutcore is now installed and you can head to the guides to start using it right away!
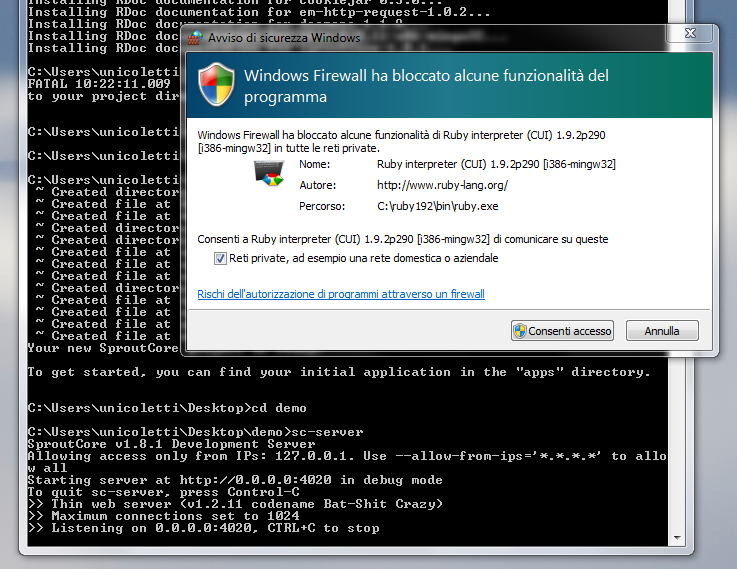
The first time you start sc-server Windows Firewall might ask you to allow the ruby process to open a network port on your computer, just say yes or you won't be able to use the live preview of your apps.
If you're worried about security remember that Sproutcore 1.8 and higher only allows connections from localhost by default, so it's pretty tight.
Comments